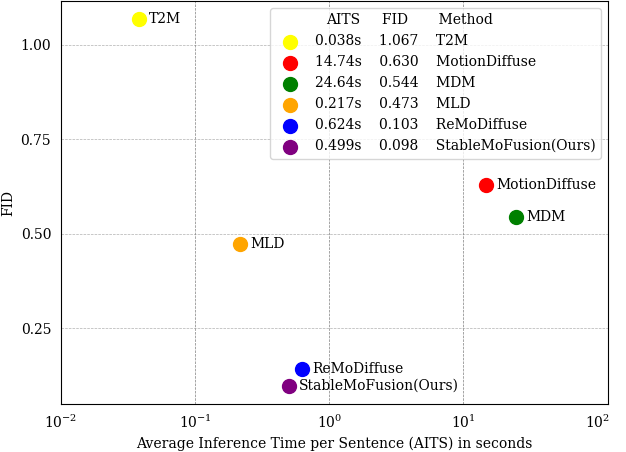
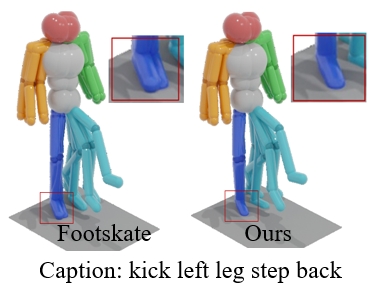
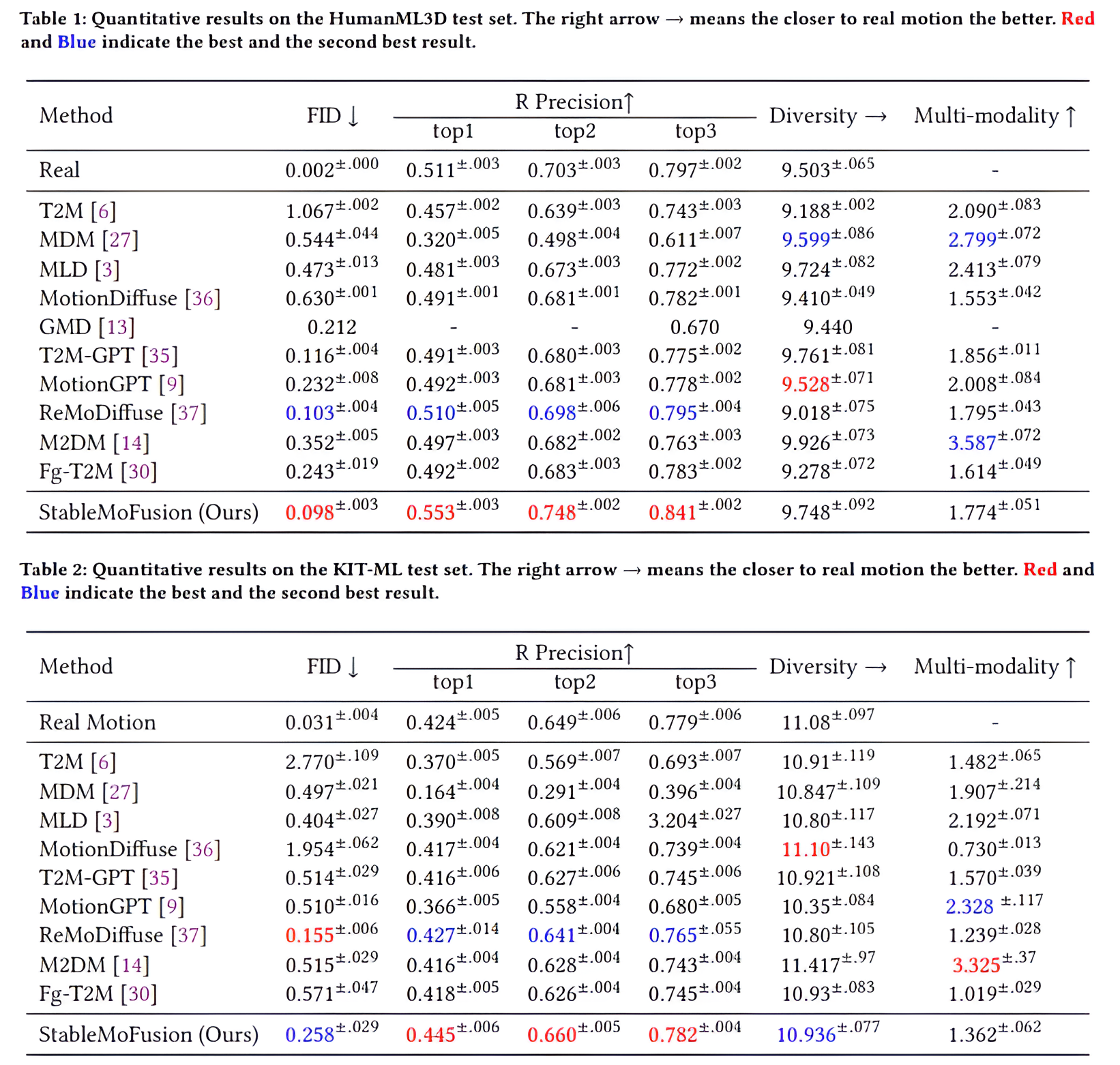
Thanks to the powerful generative capacity of diffusion models, recent years have witnessed rapid progress in human motion generation. Existing diffusion-based methods employ disparate network architectures and training strategies. The effect of the design of each component is still unclear. In addition, the iterative denoising process consumes considerable computational overhead, which is prohibitive for real-time scenarios such as virtual characters and humanoid robots. For this reason, we first conduct a comprehensive investigation into network architectures, training strategies, and inference processs. Based on the profound analysis, we tailor each component for efficient high-quality human motion generation. Despite the promising performance, the tailored model still suffers from foot skating which is an ubiquitous issue in diffusion-based solutions. To eliminate footskate, we identify foot-ground contact and correct foot motions along the denoising process. By organically combining these well-designed components together, we present StableMoFusion, a robust and efficient framework for human motion generation. Extensive experimental results show that our StableMoFusion performs favorably against current state-of-the-art methods.

@article{huang2024stablemofusion,
title={StableMoFusion: Towards Robust and Efficient Diffusion-based Motion Generation Framework},
author = {Huang, Yiheng and Hui, Yang and Luo, Chuanchen and Wang, Yuxi and Xu, Shibiao and Zhang, Zhaoxiang and Zhang, Man and Peng, Junran},
journal = {arXiv preprint arXiv: 2405.05691},
year = {2024}
}